

Friday, February 06, 2009
Continuing with the coverage of the interim Digital Britain report, something has been bothering me since I read it, so I went back and browsed through it again until I realised what it was. According to the UK's chief technology policy-makers, we still seem to be living in the 20th century. Why? Several reasons: the only mention to Web 2.0 is in the glossary; some of the technologies being pushed are proved failures with the public; it believes DRM offers a solution to piracy; it blatantly ignores the content delivery revolution that is about to take place; but most importantly, it ignores user-generated content by insisting on the outdated view of the top-down content provider.
Labels: ben, mea culpa, policy
Tuesday, February 03, 2009
- The Berne Convention precipitated the creation of modern copyright law
- Early legislators tried to qualify the scope of copyright
- 20th century legislators paid little attention to the question of incentive or production
- Copyright does not confer an automatic right of remuneration
- Legislators did not try to "balance" the interests of owners and users
- Copyright legislation regulates taxation in gross of non-commercial (or non-competing) users to the detriment of public welfare
- The structure of the Australian Copyright Act reflects sectional interest
- Public interest considerations were raised consistently in policy and legislative debates
- The pursuit of authors' rights led to the creation of analogous producers' rights
- Copyright protection did not cause the economic success of the copyright industries
- APRA's revenue demands led to the creation of Article 11 bis(2) of the Berne Convention and the Australian Copyright Tribunal
- The record industry asserted the mechanical performing right opportunistically
- The role of individual agency is underestimated in analysis of copyright
- The commercial struggle for control over the broadcast of sport precipitated the Gregory Committee enquiry
- The origins of Australian copyright policy orthodoxy lie in the Spicer Report and the second reading in the Senate of the 1968 Copyright Bill
- The parallel importation provisions of the Australian Copyright Act were carried over from imperial legislation
- Australian legislative debate has seen two great statements of principle: the first over the posthumous term and the second over import controls
- The content of the modern copyright law of Australia is the entire creation of international conventions and British precedents
- Doubts over term persisted at the official level until the 1950s
Friday, January 30, 2009
Those interested in digital copyright policy might be interested in the UK's Department of Culture, Media and Sport's 'Digital Britain' Interim Report, which was released this week.I like the idea that the Government might not just be about maintaining the status quo. I often feel that the 'majority opinion' concept is ignored (not only in the field of copyright).
http://www.culture.gov.uk/what_we_do/broadcasting/5631.aspx
Section 3.2 seems particularly relevant:
'There is a clear and unambiguous distinction between the legal and illegal sharing of content which we must urgently address. But, we need to do so in a way that recognises that when there is very widespread behaviour and social acceptability of such behaviour that is at odds with the rules, then the rules, the business models that the rules have underpinned and the behaviour itself may all need to change.'
It also recommends the creation of a Rights Agency to:
'bring industry together to agree how to provide incentives for legal use of copyright material; work together to prevent unlawful use by consumers which infringes civil copyright law; and enable technical copyright-support solutions that work for both consumers and content creators. The Government also welcomes other suggestions on how these objectives should be achieved.'
Labels: ben, guest post, policy
Thursday, January 22, 2009
Labels: ben, conferences, lca2009
Tuesday, December 02, 2008
But when I read about this on lessig.org, I went to change.gov and couldn't find any reference to Creative Commons. I looked at the HTML source and there was no reference to Creative Commons. It turns out that there is a page on the site about copyright policy, and this has a statement that covers all other pages on the site.
If this kind of licensing (having one page on your site that states that all other pages are licensed, and then linking to that page from all other pages on the site) is common (and I think it is), it means that just counting links to Creative Commons (or any other licence, for that matter) gives you a pretty bad estimation of the number of licensed pages out there.
As an example of what I'm talking about, consider the following comparison:
- apsa.anu.edu.au, 230 pages linking to Creative Commons licences, of about 655 pages. (But please don't ask me which pages don't link to Creative Commons licences, because I can't figure it out. That would be another blog post.)
- change.gov, 1 page linking to a Creative Comons licence, of about 432 pages.
I beg to differ.
(For more on this topic, and some ways it can be tackled, see my paper from iSummit. And stay tuned for more.)
(via lessig.org, via reddit.com)
Labels: ben, isummit08, lessig, quantification
Wednesday, November 26, 2008
Some of the earlier questions are oriented towards content creators. I answered 'not applicable' to a lot of them. I thought the question that asks you to define non-commercial use was interesting. I'll share mine in the comments on this post, and I encourage you to do the same (so don't read the comments until you've done the questionaire!).As previously announced, Creative Commons is studying how people understand the term “noncommercial use”. At this stage of research, we are reaching out to the Creative Commons community and to anyone else interested in public copyright licenses – would you please take a few minutes to participate in our study by responding to this questionnaire? Your response will be anonymous – we won’t collect any personal information that could reveal your identity.
Because we want to reach as many people as possible, this is an open access poll, meaning the survey is open to anyone who chooses to respond. We hope you will help us publicize the poll by reposting this announcement and forwarding this link to others you think might be interested. The questionnaire will remain online through December 7 or until we are overwhelmed with responses — so please let us hear from you soon!
Questions about the study or this poll may be sent to noncommercial@creativecommons.org.
Labels: ben, Creative Commons, guest post
Thursday, October 30, 2008
There is copyright in a work if:Yeah, that's it with about 90% of the words taken out. Legal readers, please correct me if that's wrong. (I can almost feel you shouting into the past at me from in front of your computer screens.)
- The author is Australian; or
- The first publication of the work was in Australia
So to explain a little further, there's copyright under Section 32 in all works by Australian authors, and all works by any authors that publish their works in Australia before publishing them elsewhere. There's also a definition of 'Australian' (actually 'qualified person'), but it's not particularly interesting. And there's some stuff about copyright in buildings, and people who died, and works that took a long time to produce.
Anyway, what good is this to me? Well, it makes for a reasonable definition of Australian copyrighted work. Which we can then use to define the Australian public domain or the Australian commons, assuming we have a good definition of public domain or commons.
It's a very functional definition, in the sense that you can decide for a given work whether or not to include it in the class of Australian commons.
Compare this with the definition ('description' would be a better word) I used in 2006:
Commons content that is either created by Australians, hosted in Australia, administered by Australians or Australian organisations, or pertains particularly to Australia.Yuck! Maybe that's what we mean intuitively, but that's a rather useless definition when it comes to actually applying it. Section 32 will do much better.
Thanks, Bond!
Wednesday, October 29, 2008
Back at iSummit '08, there was a presentation by Eric E. Johnson, Associate Professor at the University of North Dakota Law Faculty. In fact a full paper is available on the iSummit research track website, here.
You could read the full paper but I'm not expecting you to. I only browsed it myself. But I sat down for a while and talked to Eric, and his ideas were interesting. I think that's the thing that impressed me most about him. He was thinking outside the square (apropos, try to join these 9 dots with 4 straight lines, connected end-to-end; hint: start at a corner).
{kind=link}
Hmm... I probably just lost half my readers, and I didn't even get to Copysquare and Konomark.
This is Konomark:

It's a way for you to say you're willing to share your intellectual property. It is not a licence. It is not a legal mechanism; it has no legal effect. It's the IP equivalent of this t-shirt. You don't want to grant an irrevocable licence to all, but if people ask you for permission to re-use or re-purpose your work, there's a good chance you'll say yes, and you certainly won't be offended that they asked. It's one brick in the foundation of a culture of sharing. I think Lessig would approve.
This is Copysquare:
Okay, that's just the icon. Copysquare is actually a licence. I'm not sure if it's fully developed yet, but it's close. It's main focus is for people who want to create small, quality creative works that can be included in larger productions, such as movies.
The example Eric gave is a cityscape scene in a TV show, where most of the show is filmed indoors, but there are these little clips that remind the viewer of the geographic location of the story. The show that springs to mind is House, MD. I'll quote Wikipedia:
Exterior shots of Princeton-Plainsboro Teaching Hospital are actually of Princeton University's Frist Campus Center, which is the University's student center. Filming does not, however, take place there. Instead, it takes place on the FOX lot in Century City.Here's what Eric E. Johnson said to explain the licence (from his blog post about it, also linked above):
Copysquare uses three basic license provisions to pursue its aims: (1) a requirement of notification, (2) a right to reject, and (3) “favored nations” treatment.He goes on to give this paraphrasing of the licence:
"You can use my creative work – film footage, picture, sound effect, etc. – in your creative work, but you must notify me that you are doing so (the notification provision), give me a chance to opt out (the right to reject), and you need not pay me or credit me, but if you pay or provide credit to others for the same kind of contribution, you must pay me and credit me on an equal basis (the favored-nations provision).”So say you were the person who took that aerial shot of the Princeton Campus. You put your stuff on the web and copysquare it. Someone uses it in their YouTube videos, uncredited, not-paid for, but lets you know first and so that's cool. Someone else tries to use it in a McCain campaign add, and you assert your right to reject. And the production crew from House, MD., use it, tell you, credit you (because they credit others) and pay you (because they pay others). And everyone is happy, except probably not McCain because he is way behind in the polls right now.
I'm not the law expert, but if it works like this, I think it's pretty neat. I like the favoured nations idea: if you're producing a work on a shoestring budget, use my contribution freely; but if you're paying others, pay me too. Note that this is not in fact about whether your project is for a commercial product. It's about whether it's a commercial production. The idea, as Eric explained to me, is that you're happy for small time players, say independent film producers, to use your work. But if there are credits in that independent film, you want to be in them. And if Hollywood is going to use your work, you want a little something financially, just like everyone else working on the film is getting.
Damn, I thought this was going to be a short blog post. Well, I guess it was for those of you who got distracted by the nine-dots puzzle and stopped reading. (Didn't try? There's still time.)
A commons of copysquared material?
So around about when Eric was giving his presentation at iSummit, I was thinking about how to define 'the commons' (for my purposes). It was something I wrote about in my paper and talked about in my presentation. And I realised that by my definition, konomark and copysquare material weren't included. In fact it's how I came to talk to Eric, and I put it to him that copysquare wasn't a commons based licence.
No surprise, he accepted my argument (it was, after all, only an argument from definition), but we both agreed that this doesn't make copysquare any less useful. Anything that helps the little guy get noticed, get credited, get paid if his work is useful enough, and promotes sharing, has got to be good.
It seems to me that konomark and copysquare each fill a niche in the sharing space. In fact niches that, before iSummit, I hadn't realised existed.
Wednesday, September 10, 2008
I'm currently preparing a paper on the Open Source software developer's perspective on software patents (with a friend of mine, Owen Jones, who has the real expertise in patents), and so naturally I was interested in what the expert panel had to say about software patents. I have to admit I haven't thoroughly worked through it yet, but here is a paragraph that I think is very interesting, from the initial overview chapter:
"Intellectual property is also critical to the creation and successful use of new knowledge – particularly the 'cumulative' use of knowledge as an input to further, better knowledge. In this regard, particularly in new areas of patenting such as software and business methods, there is strong evidence that existing intellectual property arrangements are hampering innovation. To address this, the central design aspects of all intellectual property needs to be managed as an aspect of economic policy. Arguably, the current threshold of inventiveness for existing patents is also too low. The inventive steps required to qualify for patents should be considerable, and the resulting patents must be well defined, so as to minimise litigation and maximise the scope for subsequent innovators." (page xii)I think this is a great admission. First, it recognises that we need to ensure that our current innovations can contribute effectively to future innovations. Then it acknowledges that patents are granted too easily, and specifically mentions software patents as an area where more harm is being done than good.
Maybe I'm reading a little too much into it. Or maybe I'm just reading between the lines.
Labels: ben, free software, open source, patents
Thursday, August 28, 2008
The Software Freedom Law Centre has put out a guide that tells software vendors how to make sure they're complying with the GPL (see link, above). It's not hard to comply, but there are some good tips in there.
An example is to make sure you don't have a build guru - someone without whom your organisation/team could not build your software. Because if you couldn't build your software without your build guru, then people you distribute it to don't have much of a chance.
It also talks about what your options actually are in terms of basic compliance. So for example one thing I didn't know is that in GPL v3, they made it much more explicit how you can distribute source code, and that technologies such as the Web or Bit Torrents are acceptible. For example, peer-to-peer distribution of source code is acceptible as long as that is the medium being used to distribute the (built) software.
There's more good stuff in there, and even though I'm no Free Software vendor, it's an interesting read just from the perspective of an insight into how Free Sofrware compliance really works.
(Hat tip: Roger Clarke)
Labels: ben, compliance, Dr Roger Clarke, free software, gpl
Tuesday, August 05, 2008
After the day finished, we all went to this big park, Moerenuma park I think it was called. There was silly dancing, of which I took part, but some people didn't take part and instead took pictures. Somewhere on the internet, you can probably find a picture of me dancing crazily, and for those readers who don't already know what I look like, try Flickr.
Catherine (my partner; did I mention she took the week off to come with me to Japan?) and I spent the weekend in Sapporo. We were invited by Robert Guerra to go for a day trip to the coast, but Catherine wasn't feeling well so we just hung around Sapporo, went shopping, and ate (more) good ramen.
Then it was a train to New Chitose airport, flying to Tokyo, train to Narita, overnight flight back to Sydney, and domestic flight to Canberra. I can't say it was much fun, and it turns out that sleeping on a plane (economy class, at least) is hard, though I did watch two movies: Kung Fu Panda and Red Belt. The former was definitely the best, though the latter was worth watching too.
But actually I think the best thing about the trip home was on the train from Haneda (Tokyo) to Narita airport, as the sun was setting. I only caught a few glimpses, but they were memorable: a very red sun through thin white cloud.
Friday, August 01, 2008
Labels: AustLII, ben, housekeeping
Thursday, July 31, 2008
In the same session, there was also a great talk by Juan Carlos De Martin about geo-location of web pages, but it was actually broader than that and included quantification issues. Read more about that here.
Tomorrow, the research track is going to talk about the future of research about the commons. Stay tuned.
Labels: ben, isummit08, quantification, research
Tuesday, July 08, 2008
Representatives from Australia include members of the Creative Commons Australia team, Delia Browne and our very own Ben Bildstein. Ben will be presenting on quantification of the digital commons, and if you've been following Ben's work about quantification here at the House of Commons, then you won't want to miss his presentation (read more about it here).
And that's enough of a shameless plug for one day...
Labels: ben, catherine, conferences, Creative Commons
Friday, June 06, 2008
Thursday, June 05, 2008
Of course, you can still read everything on the main page.
Labels: ben
Friday, May 23, 2008
Okay, so gardening. I'll make it quick. I read in my bonsai book that if you have problems propagating from cuttings, you can grow roots on the original plant in a process called air-layering:

I tried that with my dwarf schefflera (at least I think that's what it is). Here's the parent plant (it's in a pot with 2 chillies and a mint):

But the air layer failed. No roots grew. And as you probably guessed I failed with cuttings, too. But I don't like giving up, so I stuck the cutting in some water:

It has done well. It's in a tall thin jar half full of water, in a pot that's backfilled with pebbles. This keeps the rooting part warm, which I understand is important. It is now finally growing roots:

By the way, there was no sign of those roots when it was being air layered - they've all popped out since it has been in the water. I had it outside, but a couple of the roots died and I decided it was too cold out there so I bought it inside. And today I noticed there are lost more roots starting to stick out through the bark (from cracks that run in the direction of the stem, not from those popcorn-looking bits).
So here's my conclusion about air layering schefflera (umbrella trees). There's nothing to be gained from cutting a ring of bark off. The roots don't grow out of the cut bark - they just grow out of normal bark. In fact, they grow out of the brown ~2mm long cracks you can see on every part of every branch.
In summary:
- If you're going to air layer a schefflera, the important points are making sure it's very wet and not cutting through the bark (though it may turn out that cutting through the bark encourages root production)
- To strike a cutting, focus on keeping the rooting area (which is the bark) wet
- But at the same time, remember that the cutting will drink through the bottom of the cutting, so make sure it is a clean cut. It easily rots. Mine did, and I just cut an extra 5mm of bark off to keep it healthy.
Wednesday, May 21, 2008
- has a link to a known licence URL
- has a link that has rel="license" attribute in the tag, and a legal expert confirms that the link target is a licence URL
- has a meta tag with name="dc:rights" content="URL", and an expert confirms that the URL is a licence
- has embedded or external RDF+XML with license rdf:resource="URL"
- natural language, such as "This web page is licensed with a Creative Commons Attribution 1.0 Australia License"
- system is told by someone it trusts
- URL is in rel="license" link tag, expert confirms
- URL is in meta name="dc:rights" tag, expert confirms
- URL is in RDF license tag
- page contains an exact copy of a known licence
- system is told by someone it trusts
Labels: ben, quantification
The pages were drawn randomly from the dataset, though I'm not sure that my randomisation is great - I'll look into that. As I said in a previous post, the data aims to be a broad crawl of Australian sites, but it's neither 100% complete nor 100% accurate about sites being Australian.
By my calculations, if I were to run my analysis on the whole dataset, I'd expect to find approximately 1.3 million pages using rel="licence". But keep in mind that I'm not only running the analysis over three years of data, but that data also sometimes includes the same page more than once for a given year/crawl, though much more rarely than, say, the Wayback Machine does.
And of course, this statistic says nothing about open content licensing. I'm sure, as in I know, there are lots more pages out there that don't use rel="license".
(Tech note: when doing this kind of analysis, there's a race between I/O and processor time, and ideally they're both maxed out. Over last night's analysis, the CPU load - for the last 15 minutes at least, but I think that's representative - was 58%, suggesting that I/O is so far the limiting factor.)
Labels: ben, quantification, research
Monday, May 19, 2008
First, the National Library's crawls were outsourced to the Internet Archive, which is a good thing - it's been done well, the data is in a well defined format (a few sharp edges, but pretty good), and there's a decent knowledge-base out there already for accessing this data.
Now, there are two ways that IA chooses to include a page as Australian:
- domain name ends in '.au' (e.g. all web pages on the unsw.edu.au domain)
- IP address is registered as Australian in a geolocation database
Actually, there is a third kind of page in the crawls. The crawls were done with a setting that included some pages linked directly from Australian pages (example: slashdot.org), though not sub-pages of these. I'll have to address this, and I can think of a few ways:
- Do a bit of geolocation myself
- Exclude pages where sibling pages aren't in the crawl
- Don't make national-oriented conclusions, or when I do, restrict to the .au domains
- Argue that it's a small portion so don't worry about it
(Thanks to Alex Osborne and Paul Koerbin from the National Library for detailing the specifics for me)
Labels: ben
Possible outcomes from this include:
- Some meaningful consideration of how many web pages, on average, come about from a single decision to use a licence. For example, if you licence your blog and put a licence statement into your blog template, that would be one decision to use the licence, arguably one licensed work (your blog), but actually 192 web pages (with permalinks and all). I've got a few ideas about how to measure this, which I can go in to more depth about.
- How much of the Australian web is licensed, both proportionally (one page in X, one web site in X, or one 'document' in X), and in absolute terms (Y web pages, Y web sites, Y 'documents').
- Comparison of my results to proprietary search-engine based answers to the same question, to put my results in context.
- Comparison of various licensing mechanisms, including but not limited to: hyperlinks, natural language statements, dc rights in tags, rdf+xml.
- Comparison of use of various licences, and licensing elements.
- Changes in the answers to these questions over time.
Labels: ben, licensing, open content, quantification, research
Thursday, May 01, 2008
I said I'd like to see an interface that (among other nice-to-haves) answers questions like "give me everything you've got from cyberlawcentre.org/unlocking-ip", and it turns out that that's actually possible with The Wayback Machine. Not in a single request, that I know of, but with this (simple old HTTP) request: http://web.archive.org/web/*xm_/www.cyberlawcentre.org/unlocking-ip/*, you can get a list of all URLs under cyberlawcentre.org/unlocking-ip, and then if were to want to you could do another HTTP request for each URL.
{kind=link}
Pretty cool actually, thanks Alex.
Now I wonder how big you can scale those requests up to... I wonder what happens if you ask for www.*? Or (what the heck, someone has to say it) just '*'. I guess you'd probably break the Internet...
Wednesday, April 30, 2008
Okay, so here's the latest results, including hyperlinks to searches for you to try them yourself:
- all (by regex: .*) : 36,700,000
- gpl : 8,960,000
- lgpl : 4,640,000
- bsd : 3,110,000
- mit : 903,000
- cpl : 136,000
- artistic : 192
- apache : 156
- disclaimer : 130
- python : 108
- zope : 103
- mozilla : 94
- qpl : 86
- ibm : 67
- sleepycat : 51
- apple : 47
- lucent : 19
- nasa : 15
- alladin : 9
And here's a spreadsheet with graph included: However, note the discontinuity (in absolute and trend terms) between approximate and specific results in that (logarithmic) graph, which suggests Google's approximations are not very good.
Labels: ben, free software, licensing, quantification, search
Tuesday, April 08, 2008
I just did this analysis of Google's and Yahoo's capacities for search for commons (mostly Creative Commons because that's in their advanced search interfaces), and thought I'd share. Basically it's an update of my research from Finding and Quantifying Australia's Online Commons. I hope it's all pretty self-explanatory. Please ask questions. And of course point out flaws in my methods or examples.
Also, I just have to emphasise the "No" in Yahoo's column in row 1: yes, I am in fact saying that the only jurisdiction of licences that Yahoo recognises is the US/unported licences, and that they are in fact ignoring the vast majority of Creative Commons licences. (That leads on to a whole other conversation about quantification, but I'll leave that for now.)
(I've formatted this table in Courier New so it should come out well-aligned, but who knows).
Feature | Google | Yahoo |
------------------------------+--------+-------+
1. Multiple CC jurisdictions | Yes | No | (e.g.)
2. 'link:' query element | No | Yes | (e.g. G, Y)
3. RDF-based CC search | Yes | No | (e.g.)
4. meta name="dc:rights" * | Yes | ? ** | (e.g.)
5. link-based CC search | No | Yes | (e.g.)
6. Media-specific search | No | No | (G, Y)
7. Shows licence elements | No | No | ****
8. CC public domain stamp *** | Yes | Yes | (e.g.)
9. CC-(L)GPL stamp | No | No | (e.g.)
* I can't rule out Google's result here actually being from <a rel="license"> in the links to the license (as described here: http://microformats.org/wiki/rel-license).
** I don't know of any pages that have <meta name="dc:rights"> metadata (or <a rel="licence"> metadata?) but don't have links to licences.
*** Insofar as the appropriate metadata is present.
**** (i.e. doesn't show which result uses which licence)
Notes about example pages (from rows 1, 3-5, 8-9):
- To determine whether a search engine can find a given page, first look at the page and find enough snippets of content that you can create a query that definitely returns that page, and test that query to make sure the search engine can find it (e.g. '"clinton lies again" digg' for row 8). Then do the same search as an advanced search with Creative Commons search turned on and see if the result is still found.
- The example pages should all be specific with respect to the feature they exemplify. E.g. the Phylocom example from row 9 has all the right links, logos and metadata for the CC-GPL, and particularly does not have any other Creative Commons licence present, and does not show up in search results.
Labels: ben, Creative Commons, quantification, search
Tuesday, February 19, 2008
http://www.archive.org/web/researcher/intended_users.php
I'll certainly be looking into this further.
(update: On further investigation, it doesn't look so good. http://www.archive.org/web/researcher/researcher.php says:
We are in the process of redesigning our researcher web interface. During this time we regret that we will not be able to process any new researcher requests. Please see if existing tools such as the Wayback Machine can accommodate your needs. Otherwise, check back with us in 3 months for an update.This seems understandable except for this, on the same page:
This material has been retained for reference and was current information as of late 2002.That's over 5 years. And in Internet time, that seems like a lifetime. I'll keep investigating.)
Labels: ben, open access, quantification
The very basics of web search
Web search engines, like Google, Yahoo, Live, etc., are made up of a few technologies:
- Web crawling - downloading web pages; discovering new web pages
- Indexing - like the index in a book: figure out which pages have which features (meaning keywords, though there may be others), and store them in separate lists for later access
- Performing searches - when someone wants to do a keyword search, for example, the search engine can look up the keywords in the index, and find out which pages are relevant
But what I'm interested in here is web crawling. Perhaps that has something to do with the fact that online commons quantification doesn't require indexing or performing searches. But bear with me - I think it's more than that.
A bit more about the web crawler
There are lots of tricky technical issues about how to do the best crawl - to cover as many pages as possible, to have the most relevant pages possible, to maintain the latest version of the pages. But I'm not worried about this now. I'm just talking about the fundamental problem of downloading web pages for later use.
Anyone who is reading this and hasn't thought about the insides of search engines before is probably wondering at the sheer amount of downloading of web pages required, and storing them. And you should be.
They're all downloading the same data
So a single search engine basically has to download the whole web? Well, some certainly have to try. Google, Yahoo and Live are trying. I don't know how many others are trying, and many of them may not be publicly using their data so we may not see them. There clearly are more at least than I've ever heard of - take a look at Wikipedia's robots.txt file: http://en.wikipedia.org/robots.txt.
My point is why does everyone have to download the same data? Why isn't there some open crawler somewhere that's doing it all for everyone, and then presenting that data through some simple interface? I have a personal belief that when someone says 'should', you should* be critical in listening to them. I'm not saying here that Google should give away their data - it would have to be worth $millions to them. I'm not saying anyone else should be giving away all their data. But I am saying that there should be someone doing this, from an economic point of view - everyone is downloading the same data, and there's a cost to doing that, and the cost would be smaller if they could get together and share their data.
Here's what I'd like to see specifically:
- A good web crawler, crawling the web and thus keeping an up-to-date cache of the best parts of the web
- An interface that lets you download this data, or diffs from a previous time
- An interface that lets you download just some. E.g. "give me everything you've got from cyberlawcentre.org/unlocking-ip" or "give me everything you've got from *.au (Australian registered domains)" or even "give me everything you've got that links to http://labs.creativecommons.org/licenses/zero-assert/1.0/us/"
- Note that in these 'interface' points, I'm talking about downloading data in some raw format, that you can then use to, say, index and search with your own search engine.
* I know.
Labels: ben, open access, quantification, search
Monday, February 18, 2008
If you look around, you can probably find some graphs based on this data, and that's probably interesting in itself. Tomorrow I'll see about dusting off my Perl skills, and hopefully come up with a graph of the growth of Australian CC licence usage. Stay tuned.
* If you knew about this, why didn't you tell me!
Labels: ben, Creative Commons, licensing, quantification
Thursday, February 14, 2008
There are two options here. The first is a waiver, where you can "waive all copyrights and related or neighboring interests that you have over a work". The second is an assertion, where you can "assert that a work is free of copyright as a matter of fact, for example, because the work is old enough to be in the public domain, or because the work is in a class not protected by copyright such as U.S. government works."
It's pretty neat. I've thought the idea of asserting a work's copyright status, as a matter of fact, was a good idea, and not just limited to the public domain, but also for other classes of usage rights.
Okay, so that's basically the CC0 story. I've tried it out with a trivial web page I think I would otherwise have copyright in - the result is at the bottom of this post. But I must say I'm slightly disappointed in the lack of embedded metadata. Where's the RDF? As I've talked about before, when you do things with RDF, you allow sufficiently cool search engines to understand your new technology (or licence) simply by seeing it, without first having to be told about it.
Here's my example waiver:
To the extent possible under law,
Ben Bildstein has waived all copyright, moral rights, database rights, and any other rights that might be asserted over Sensei's Library: Bildstein/Votes.
Labels: ben, Creative Commons, search
Friday, October 19, 2007
House of Commons friend and ANU academic Dr. Matthew Rimmer has called for Australia to follow the lead of US Democrats presidential candidate hopeful Barack Obama and allow these debates to be made "freely accessible across all media and technology platforms" (See the ANU Press Release here). In the United States, Obama suggested that the US Democrat debates be either placed in the public domain or licensed under a Creative Commons licence.
Dr Rimmer has said that
"Whichever television networks or internet media end up broadcasting the federalThe House of Commons strongly supports Dr. Rimmer's suggestion. It is an unusual one in an Australian context - in the United States, there is no copyright in works produced by the US government and thus there is at least a precedent for this type of action. There is also the First Amendment guarantee of freedom of speech, which arguably means that this type of content gains even greater significance. However, there has been a shift in this campaign to Australian political parties embracing all that the digital revolution has to offer (just type 'Kevin07' into Google, for example). A pledge by the parties to make debate materials freely available and accessible via sites such as YouTube would be both a positive and definite step for Australian democracy in the digital age.
election debates, it’s important to the health of our democracy that people are
free to capture and distribute the dialogue of our prospective leaders so that
they can make a more informed decision."
The logisitics of such a proposition has also caused much discussion amongst House of Commons housemates. Housemate Ben writes:
"I think election debates should belong to the commons, at least insofar asIn response, Housemate Abi has agreed (and I concur) that the parody or satire fair dealing exception in the Copyright Act could probably be used to create parodies, although there issue regarding modifications may need to be addressed.
complete reproduction is concerned. However, I do see that there are good
reasons not to allow modifications, because they could be used to spread
disinformation at such a crucial time. For these reasons, a licence such as
Creative Commons No Derivatives would be appropriate (as opposed to, say, a
public domain dedication). It's also worth noting that, even under such a
licence, derivatives could be made for the purpose of satire (correct me if I'm
wrong here!), and that could perhaps be both a good and a bad thing (I'm not
sure to what extent you could use the satire exception to spread
disinformation)."
For more information on Dr. Rimmer's proposal, the ANU Press Release can be found here.
Labels: abi, ben, catherine, Creative Commons, open content, parody, youtube
Tuesday, October 09, 2007
So without further ado, here's the link: Advance Australia Fair? The Copyright Reform Process.
Now, I'm no legal expert, and I have to admit the article was kind of over my head. But, by way of advertisement, here are some keywords I can pluck out of the paper as relevant:
- Technological protection measures (TPMs)
- Digital rights management (DRM)
- The Australia-US Free Trade Agreement (AUSFTA)
- The Digital Agenda Act (forgive me for not citing correctly!)
- The Digital Millennium Copyright Act (DMCA)
- The World Intellectual Property Organization (WIPO)
Labels: abi, ben, catherine, legislation, research
Thursday, October 04, 2007
I'm working on human embryonic stem cell research and patenting of those in Australia but from overseas. I was wondering whether you are aware of any Australian IP (that would cover patents) or patent blogs maybe.I don't know of any such blogs, but I have to admit to not paying as much attention to the world of patents as I do of copyright. But for the sake of being helpful I decided to ask around. So if anyone has any good Australian patent law related web resources, drop a comment on this post and I'll pass it on.
Wednesday, October 03, 2007
Anyway, the point is, it won't be getting to court because the defendants capitulated. According to Linux Watch, Monsoon Multimedia "admitted today that it had violated the GPLv2 (GNU General Public License version 2), and said it will release its modified BusyBox code in full compliance with the license."
This shows that the system works. The GPL must be clear enough that it is obvious what you can't do. (Okay, there's still some discussion, but on the day to day stuff, everything is going just fine).
Friday, August 24, 2007
Here's the run-down:
- "Softpedia is a library of over 35,000 free and free-to-try software programs for Windows and Unix/Linux,games and drivers. We review and categorize these products in order to allow the visitor/user to find the exact product they and their system needs," from the help page.
- Wikipedia has a page on it, which interestingly says that "it is one of the top 500 websites according to Alexa traffic ranking."
Tuesday, August 14, 2007
I was going to comment on this TechnoLlama post, but then I thought, "why not just blog about it?"
Now, before I go any further, let me reiterate, I am not a lawyer, I have no formal background in law, and the Unlocking IP project is not even particularly about patents.
Get to the point, Ben.
Okay, okay. My point is this, and please correct me if I am wrong (that's why I'm making this a whole post, so you can correct me in the comments): as I understand it, the abstract of a patent does not say what the invention is, but rather it describes the invention. I.e. the abstract is more general that the invention.
For example, say I had a patent for... *looks around for a neat invention within reach*... my discgear. Well the abstract might say something like
A device for storing discs, with a selector mechanism and an opening mechanism such that when the opening mechanism is invoked, the disc selected by the selector mechanism is presented.
But then the actual patent might talk about how:
- the opening mechanism is a latch;
- the discs are held in small grooves that separate them but allow them to be kept compact;
- the lid is spring loaded and damped so that when the latch is released it gently lifts up;
- there is a cool mechanism I don't even understand for having the lid hold on to the selected disc;
- said cool mechanism (the selector mechanism) has another mechanism that allows it to slide only when pressed on and not when just pushed laterally;
- etc.
To go back to the original example, an old vinyl disc jukebox (see the third image on this page) would satisfy the description in my abstract, but not infringe my patent.
{kind=link}
In summary, I'm not alarmed by the generality of the abstract in the Facebook case. But if it turns out I'm wrong, and abstract are not more general than the patents they describe, let me just say I will be deeply disturbed.
You have no idea what you're talking about
I thought I made that clear earlier, but yes that's true. Please correct me, or clarify what I've said, by comment (preferred), or e-mail (in case it's the kind of abuse you don't want on the public record).
Friday, July 20, 2007
Now, there's two possible approaches to making the RDR system probabilistic (i.e. making it predict the probability that it is wrong for a given input). First, we could try to predict the probabilities based on the structure of the RDR and which rules have fired. Alternatively, we could ask the expert explicitly for some knowledge of probabilities (in the specific context, of course).
Observational analysis
What I'm talking about here is using RDR like normal, but trying to infer probabilities based on the way it reaches its conclusion. The most obvious situation where this will work is when all the rules that conclude positive (interesting) fire and none of the rules that conclude negative (uninteresting) fire. (This does, however, mean creating a more Multiple Classification RDR type of system.) Other possibilities include watching over time to see which rules are more likely to be wrong.
These possibilities may seem week, but they may turn out to provide just enough information. Remember, any indication that some examples are more likely to be useful is good, because it can cut down the pool of potential false negatives from the whole web to something much, much smaller.
An expert opinion
The other possibility is to ask the expert in advance how likely the system is to be wrong. Now, as I discussed, this whole RDR methodology is based around the idea that experts are good at justifying themselves in context, so it doesn't make much sense to ask the expert to look at an RDR system and say in advance how likely a given analysis is to be wrong. On the other hand, it might be possible to ask the expert, when they are creating a new rule: what is the probability that the rule will be wrong (the conclusion is wrong), given that it fires (its condition is met)? And, to get a little bit more rigorous, we would ideally also like to know: what is the probability that the rule's condition will be met, given that the rule's parent fired (the rule's parent's condition was met)?
The obvious problem with this is that the expert might not be able to answer these questions, at least with any useful accuracy. On the other hand, as I said above, any little indication is useful. Also, it's worth pointing out that what we need is not primarily probabilities, but rather a ranking or ordering of the candidates for expert evaluation, so that we know which is the most likely to be useful (rather than exactly how likely it is to be useful).
Also the calculations of probabilities could turn out to be quite complex :)
Here's what I consider a minimal RDR tree for the purposes of calculating probabilities, with some hypothetical (imaginary) given probabilities.
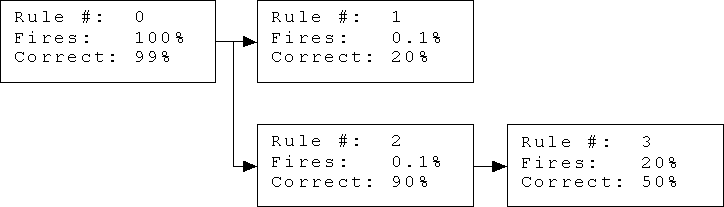
Let me explain. Rule 0 is the default rule (the starting point for all RDR systems). It fires 100% of the time, and in this case it is presumed to be right 99% of the time (simulating the needle-in-a-haystack scenario). Rules 1 and 2 are exceptions to rule 0, and will be considered only when rule 0 fires (which is all the time because it is the default rule). Rule 3 is an exception to rule 2, and will be considered only when rule 2 fires.
The conclusions of rules 0 and 3 are (implicitly) 'hay' (uninteresting), while the conclusions of rules 1 and 2 are (implicitly) 'needle' (interesting). This is because the conclusion of every exception rule needs to be different from the conclusion of the parent rule.
The percentage for 'Fires' represents the expert's opinion of how likely the rule is to fire (have its condition met) given that the rule is reached (its parent is reached and fires). The percentage for 'Correct' represents the expert's opinion of how likely the rule's conclusion is to be correct, given that the rule is reached and fires.
With this setup, you can start to calculate some interesting probabilities, given knowledge of which rules fire for a given example. For example, what is the probability of 'needle' given that rules 1 and 2 both fire, but rule 3 doesn't? (This is assumedly the most positive indication of 'needle' we can get.) What difference would it make if rule 3 did fire? If you can answer either of these questions, leave a comment.
If no rules fire, for example, the probability of 'needle' is 0.89%, which is only very slightly less than the default probability of 'needle' before using the system, which was 1%. Strange, isn't it?
Labels: artificial intelligence, ben, research
Tuesday, July 17, 2007
Ripple Down Rules
Ripple down rules is a knowledge acquisition methodology developed at the University of New South Wales. It's really simple - it's about incrementally creating a kind of decision tree based on an expert identifying what's wrong with the current decision tree. It works because the expert only needs to justify their conclusion that the current system is wrong in a particular case, rather than identify a universal correction that needs to be made, and also the system is guaranteed to be consistent with the expert's evaluation of all previously seen data (though overfitting can obviously still be a problem).
The application of ripple down rules to deep web commons is simply this: once you have a general method for flattened web forms, you can use the flattened web form as input to the ripple down rules system and have the system decide if the web form hides commons.
But how do you create rules from a list of text strings without even a known size (for example, there could be any number of options in a select input (dropdown list), and any number of select inputs in a form). The old "IF weather = 'sunny' THEN play = 'tennis'" type of rule doesn't work. One solution is to make the rule conditions more like questions, with rules like "IF select-option contains-word 'license' THEN form = 'commons'" (this is a suitable rule for Advanced Google Code Search). Still, I'm not sure this is the best way to express conditions. To put it another way, I'm still not sure that extracting a list of strings, of indefinite length, is the right way to flatten the form (see this post). Contact me if you know of a better way.
A probabilistic approach?
As I have said, one of the most interesting issues I'm facing is the needle in a haystack problem, where we're searching for (probably) very few web forms that hide commons, in a very very big World Wide Web full of all kinds of web forms.
Of course computers are good at searching through lots of data, but here's the problem: while you're training your system, you need examples of the system being wrong, so you can correct it. But how do you know when it's wrong? Basically, you have to look at examples and see if you (or the expert) agree with the system. Now in this case we probably want to look through all the positives (interesting forms), so we can use any false positives (uninteresting forms) to train the system, but that will quickly train the system to be conservative, which has two drawbacks. Firstly, we'd rather it wasn't conservative because we'd be more likely to find more interesting forms. Secondly, because we'll be seeing less errors in the forms classified as interesting, we have less examples to use to train the system. And to find false negatives (interesting forms incorrectly classified as uninteresting), the expert has to search through all the examples the system doesn't currently think are interesting (and that's about as bad as having no system at all, and just browsing the web).
So the solution seems, to me, to be to change the system, so that it can identify the web form that it is most likely to be wrong about. Then we can get the most bang (corrections) for our buck (our expert's time). But how can anything like ripple down rules do that?
Probabilistic Ripple Down Rules
This is where I think the needle in a haystack problem can actually be an asset. I don't know how to make a system that can tell how close an example is to the boundary between interesting and uninteresting (the boundary doesn't really exist, even). But it will be a lot easier to make a system that predicts how likely an example is to be an interesting web form.
This way, if the most likely of the available examples is interesting, it will be worth looking at (of course), and if it's classified as not interesting, it's the most likely to have been incorrectly classified, and provide a useful training example.
I will talk about how it might be possible to extract probabilities from a ripple down rules system, but this post is long enough already, so I'll leave that for another post.
Labels: artificial intelligence, ben, research
Thursday, July 12, 2007
Flattening a web form
The first problem is that of how to represent a web form in such a way that it can be used as an input to an automated system that can evaluate it. Ideally, in machine learning, you have a set of attributes that form a vector, and then you use that as the input to your algorithm. Like in tic-tac-toe, you might represent a cross by -1, a naught by +1, and an empty space by 0, and then the game can be represented by 9 of these 'attributes'.
But for web forms it's not that simple. There are a few parts of the web form that are different from each other. I've identified these potentially useful places, of which there may be one or more, and all of which take the form of text. These are just the ones I needed when considering Advanced Google Code Search:
- Form text. The actual text of the web form. E.g. "Advanced Code Search About Google Code Search Find results with the regular..."
- Select options. Options in drop-down boxes. E.g. "any language", "Ada", "AppleScript", etc.
- Field names. Underlying names of the various fields. E.g. "as_license_restrict", "as_license", "as_package".
- Result text. The text of each search result. E.g. (if you search for "commons"): "shibboleth-1.3.2-install/.../WrappedLog.java - 8 identical 26: package..."
- Result link name. Hyperlinks in the search results. E.g. "8 identical", "Apache"
But as far as I can tell, text makes for bad attributes. Numerical is much better. As far as I can tell. But I'll talk about that more when I talk about ripple down rules.
A handful of needles in a field of haystacks
The other problem is more about what we're actually looking for. We're talking about web forms that hide commons content. Well the interesting this about that is that there's bound to be very few, compared to the rest of the web forms on the Internet. Heck, they're not even all for searching. Some are for buying things. Some are polls.
And so, if, as seems likely, most web forms are uninteresting, if we need to enlist an expert to train the system, the expert is going to be spending most of the time looking at uninteresting examples.
This makes it harder, but in an interesting way: if I can find some way to have the system, while it's in training, find the most likely candidate of all the possible candidates, it could solve this problem. And that would be pretty neat.
Labels: ben, deep web, research
Tuesday, July 10, 2007
The deep web
Okay, so here's what I'm looking at. It's called the deep web, and it refers to the web documents that the search engines don't know about.
Sort of.
Actually, when the search engines find these documents, they really become part of the surface web, in a process sometimes called surfacing. Now I'm sure you're wondering: what kinds of documents can't search engines find, if they're the kind of documents anyone can browse to? The simple answer is: documents that no other pages link to. But a more realistic answer is that it's documents hidden in databases, that you have to do searches on the site to find. They'll generally have URLs, and you can link to them, but unless someone does, they're part of the deep web.
Now this is just a definition, and not particularly interesting in itself. But it turns out (though I haven't counted, myself) that there are more accessible web pages in the deep web than in the surface web. And they're not beyond the reach of automated systems - the systems just have to know the right questions to ask and the right place to ask the question. Here's an example, close to Unlocking IP. Go to AEShareNet and do a search, for anything you like. The results you get (when you navigate to them) are documents that you can only find by searching like this, or if someone else has done this, found the URL, and then linked to it on the web.
Extracting (surfacing) deep web commons
So when you consider how many publicly licensed documents may be in the deep web, it becomes an interesting problem from both the law / Unlocking IP perspective and from the computer science, which I'm really happy about. What I'm saying here is that I'm investigating ways of making automated systems to discover deep web commons. And it's not simple.
Lastly, some examples
I wanted to close with two web sites that I think are interesting in the context of deep web commons. First, there's SourceForge, which I'm sure the Planet Linux Australia readers will know (for the rest: it's a repository for open source software). It's interesting, because their advanced search feature really doesn't give many clues about it being a search for open source software.
And then there's the Advanced Google Code Search, which searches for publicly available source code, which generally means free or open source, but sometimes just means available, because Google can't figure out what the licence is. This is also interesting because it's not what you'd normally think of as deep web content. After all Google's just searching for stuff it found on the web, right? Actually, I class this as deep web content because Google is (mostly) looking inside zip files to find the source code, so it's not stuff you can find in regular search.
This search, as compared to SourceForge advanced search, makes it very clear you're searching for things that are likely to be commons content. In fact, I came up with 6 strong pieces of evidence that I can say leads me to believe Google Code Search is commons related.
(As a challenge to my readers, see how many pieces of evidence you can find that the Advanced Google Code Search is a search for commons (just from the search itself), and post a comment).
Labels: ben, deep web, research
This announcement acknowledges that GPLv3 "is an improved version of the license to better suit the needs of Free Software in the 21st Century," saying "We feel this is an important change to help promote the interests of Samba and other Free Software."
Unfortunately, the announcement doesn't say much about how Samba made their decision or what swayed them.
Labels: ben, free software, gpl
Friday, July 06, 2007
This is set to be a continuing theme in my research. Not because it's particularly valuable in the field of computer science, but because in the (very specific) field of online commons research, no one else seems to be doing much. (If you know something I don't about where to look for the research on this, please contact me now!)
I wish I could spend more time on this. What I'd do if I could would be another blog post altogether. Suffice it to say that I envisaged a giant machine (completely under my control), frantically running all over the Internets counting documents and even discovering new types of licences. If you want to hear more, contact me, or leave a comment here and convince me to post on it specifically.
So what do I have to say about this? Actually, so much that the subject has its own page. It's on unlockingip.org, here. It basically surveys what's around on the subject, and a fair bit of that is my research. But I would love to hear about yours or any one else's, published, unpublished, even conjecture.
Just briefly, here's what you can currently find on the unlockingip.org site:
- My SCRIT-ed paper
- My research on the initial uptake of the Creative Commons version 2.5 (Australia) licence
- Change in apparent Creative Commons usage, June 2006 - March 2007
- Creative Commons semi-official statistics
I'm also interested in the methods of quantification. With the current technologies, what is the best way to find out, for any given licence, how many documents (copyrighted works) are available with increased public rights? This is something I need to put to Creative Commons, because their licence statistics page barely addresses this issue.
Labels: ben, quantification, research
Thursday, July 05, 2007
The reason I haven't been blogging much (apart from laziness, which can never be ruled out) is that The House of Commons has become something of an IP blog. Okay, it sounds obvious, I know. And, as it seems I say at every turn, I have no background in law, and my expertise is in computer science and software engineering. And one of the unfortunate aspects of the blog as a medium is that you don't really know who's reading it. The few technical posts I've done haven't generated much feedback, but then maybe that's my fault for posting so rarely that the tech folks have stopped reading.
So the upshot of this is a renewed effort by me to post more often, even if it means technical stuff that doesn't make sense to all our readers. It's not like I'm short of things to say.
To start with, in the remainder of this post, I want to try to put in to words, as generally as possible, what I consider my research perspective to be...
Basically what I'm most interested in is the discovery of online documents that we might consider to be commons. (But remember, I'm not the law guy, so I'm trying not to concern myself with that definition.) I think it's really interesting, technically, because it's so difficult to say (in any automated, deterministic way, without the help of an expert - a law expert in this case).
And my my computer science supervisor, Associate Professor Achim Hoffman, has taught me that computer science research needs to be as broad in application as possible, so as I investigate these things, I'm sparing a thought for their applicability to areas other than commons and even law.
In upcoming posts, I'll talk about the specifics of my research focus, some of the specific problems that make it interesting, possible solutions, and some possible research papers that might come out of it in the medium term.
Friday, June 15, 2007
Selected quote:
"You're acting like some Alice-in-Wonderland character, saying that your definition of words is the only one that matter. And that others are "confused". Read up on your humpty-dumpty some day."
Labels: ben, free software, gpl
Tuesday, April 03, 2007
"By providing DRM-free downloads, we aim to address the lack of interoperability which is frustrating for many music fans. We believe that offering consumers the opportunity to buy higher quality tracks and listen to them on the device or platform of their choice will boost sales of digital music."But note the use of the term "higher quality tracks" - you can get the same tracks with a lower quality for a lower price, but with them you still get DRM. So perhaps this is partly just a way to version their products so that they extract the maximum money from consumers: Rich people will buy the expensive DRM-free tracks and not need to share them with their rich friends even though they can, and poor people will buy the cheap tracks, and although they'll want to share them with their poor friends they won't be able to.
Still, this is definitely a (small) win for consumer rights.
(hat tip: TechnoLlama)
Labels: ben
Wednesday, March 14, 2007
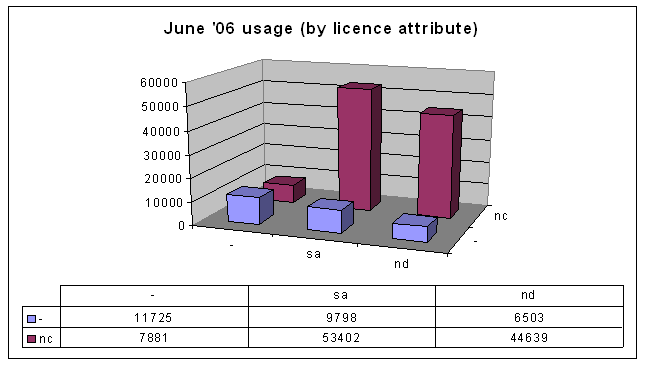 It shows that most people are using the Non-Commercial licences and restricting derivative works.
It shows that most people are using the Non-Commercial licences and restricting derivative works.That was all well and good, but then this year I revised my paper for publication in SCRIPT-ed. I wasn't going to gather the data all over again, but then I remembered that Australia now has version 2.5 Creative Commons licences, and I guessed (correctly) that the numbers would be big enough to warrant being included in the paper. Here's the data from March 2007:
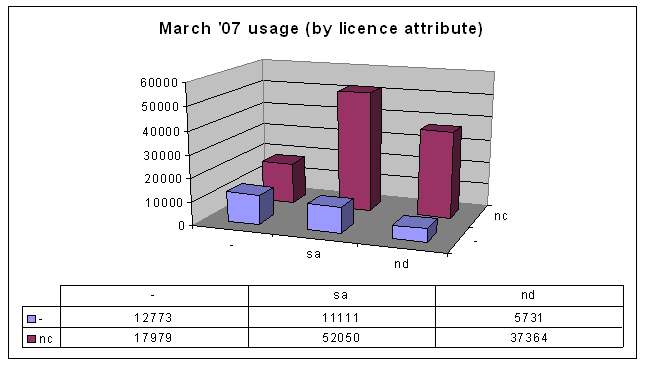
Matrix subtraction
I admit that it looks about the same, but it gets interesting when you subtract the old data from the new data, to find the difference between now and mid-2006:
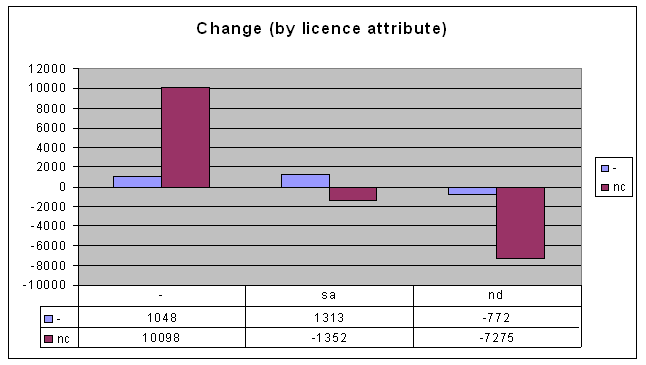 So here's my first conclusion, from looking at this graph:
So here's my first conclusion, from looking at this graph:- People are moving away from Attribution-NonCommercial-NoDerivs licences and towards Attribution-NonCommercial licences. I.e. people are tending towards allowing modifications of their works.
The jurisdiction/version dimension
Another way of looking at the data is by jurisdiction and version, instead of by the licences' attributes. Here's the data from June 2006, organised this way:
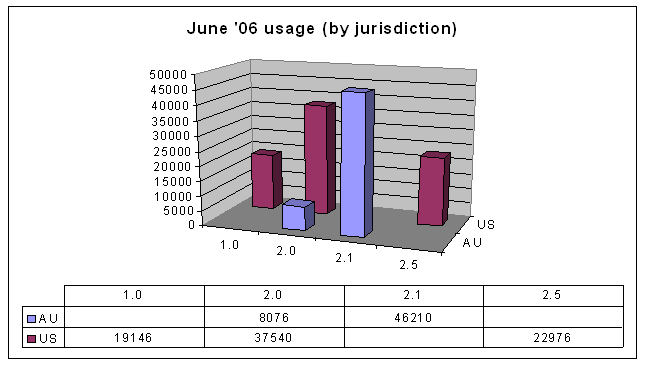 First, note that there was no data (at the time) for Australian version 1.0 and 2.5, and US version 2.1 licences. This is simply because not all jurisdictions have all licence versions.
First, note that there was no data (at the time) for Australian version 1.0 and 2.5, and US version 2.1 licences. This is simply because not all jurisdictions have all licence versions.Some people might be wondering at this stage why there are Australian web sites using US licences. I believe the reason is that Creative Commons makes it very easy to use US (now generic) licences. See http://creativecommons.org/license/, where the unported licence is the default option.
The previous graph, also, is not particularly interesting in itself, but compare that to the current data:
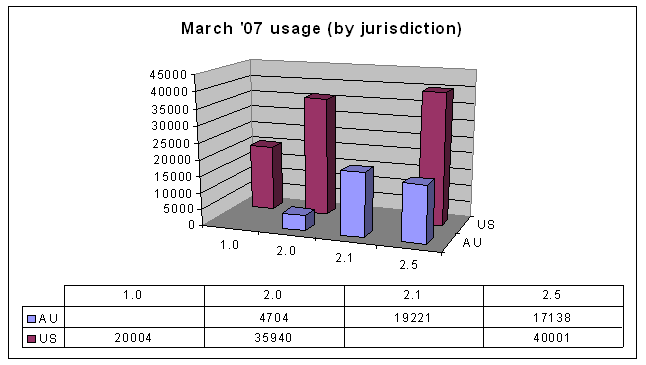
The move away from Australia version 2.1
You can see straight away that there's lots of change in the 2.1 and 2.5 version licences. But take a look at the change over the last 9 months:
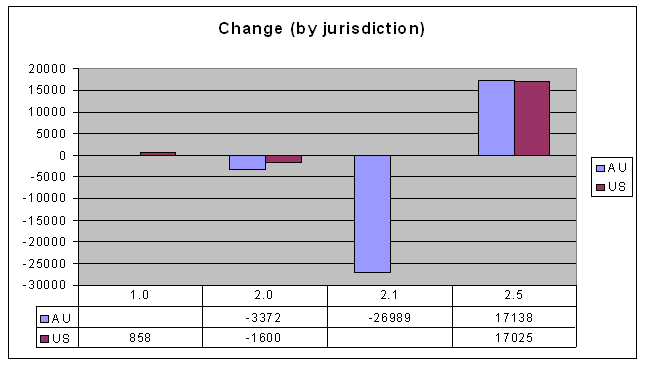 Can that be right? Australian usage of both US and Australian version 2.5 licences has increased as expected (because they are current). But why would the usage of Australian 2.1 licences go down? And by more than the amount of new usage of Australian 2.5 licences? Here are some possibilities:
Can that be right? Australian usage of both US and Australian version 2.5 licences has increased as expected (because they are current). But why would the usage of Australian 2.1 licences go down? And by more than the amount of new usage of Australian 2.5 licences? Here are some possibilities:- Some people who were using AU-2.1 licences have switched to AU-2.5, and some have switched to US-2.5 (the latter's a little hard to understand, though).
- The AU-2.1 licence usage has gone down independent of the new licences. It could even be that most of the licences were actually not real licensed works, but, for example, error messages on a web site that has a licence stamp on every page. If the web site is inadvertently exposing countless error messages, when the problem is fixed it could involve this kind of correction.
- Or my original data could have just been wrong. I know it's not cool to suggest this kind of thing: "my data? My data! There's nothing wrong with my data!" Well, even then, it could be that my methods have significant variability.
Methodology
For the record, here's how I collected the data. I did the following Yahoo searches (and 36 others). For each search, Yahoo tells you "about" how many pages are found.
- Australian use of AU-by version 2.5
- Australian use of AU-by-sa version 2.5
- Australian use of AU-by-nd version 2.5
- Australian use of AU-by-nc version 2.5
- Australian use of AU-by-nc-sa version 2.5
- Australian use of AU-by-nc-nd version 2.5
Last word
You can see a graph of the change in usage for every licence for every version and both jurisdictions here.
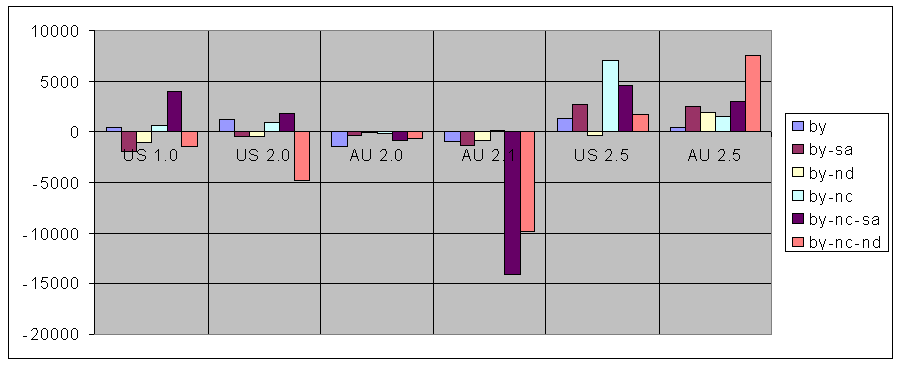{kind=link}
Labels: ben, Creative Commons, quantification
Tuesday, January 30, 2007
But in this case, (a) they're not relicensing their web pages, and more importantly (b) they seem to be doing this solely for commercial advantage - the pages are glossed with prominent Google ads. In fact, in Andres' case, I don't think they even realise the content they're stealing is licensed. If you look at some of the other content they've (most likely) stolen (e.g. http://g38.bgtoyou.com/Miscellaneous-local-events-Free-medium-psychic-reading/ or http://g91.bgtoyou.com/Body-Snatching-Updated-for-The-Times/) they do link back to the original. In fact, this is the only reason Andres found out his posts were being so copied.
So what's going on here? It looks to me like these people have an automated system to download new posts (via. RSS, most likely), and then republish them on random subdomains of bgtoyou.com. Andres suggested that it was a link farm, but I don't agree - I don't think you need content for a link farm, you can just create heaps of pages with no (or random) content and link them to each other. But if it's not a link farm, that raises two questions: If they're doing it for ad revenue, who are they expecting to read the page? And why are they bothering to link back to the originators of the posts, especially given that in doing so they're advertising they're copyright infringement?
I don't know the answer to these questions. In the mean time, it looks like Andres is going to try to enforce his licence, which is to say that he's going to try to get the infringing copies removed from bgtoyou.com. Like I said, I don't think bgtoyou was willfully breaking the licence - I think they were willfully infringing the copyright, but it will be interesting if they do realise, and then try to use the licence as a defense.
Labels: ben, infringement
Monday, January 08, 2007
- Some alternate names for the House of Commons were 'Ode to a Coffee', 'Stenchblossoms' and 'UIP Unlocked'.
- Hidden talents: Catherine was a child singer and was accepted into the Australian Youth Choir; At the ripe age of 8 Abi was a contestant on Boomerang, a children's television game show created in Hong Kong. She never received her prize; Ben is a black belt in karate.
- We all dream of very different alternate careers: Catherine would like to be the editor of US Vogue; Abi would like to take over the world; Ben would like to be a professional go player.
- Ben has dual citizenship. In Australia, his name is registered as Benjamin Mark Bildstein. In Canada, it is Benjamin Mark Noble Bildstein; Abi's full name is Abirami Paramaguru, with no middle name; Catherine's full name is Catherine Michelle Bond.
- Abi grew up in Sri Lanka, Hong Kong and Sydney; Ben grew up in Hobart; Catherine grew up in Sydney and Adelaide.
Friday, December 08, 2006
Sure, it's lots of reasons: Creative Commons has some funky technology, like RDF, that makes it easier for search engines to find licensed stuff. They've got brilliant marketing. And there are other reasons.
But something kind of disturbing just occurred to me. These search engines have Creative Commons features, and no other open content features. That's okay, but it does, in a sense, advertise Creative Commons. And this creates positive feedback: people use Creative Commons, search engines enhance support for Creative Commons, more people learn about Creative Commons, and more people use it. Etc.
So I hear people saying "yeah, but that's natural - the cream rises to the top". But it's more than that. There are people who have never heard of any type of open content licensing. And now Creative Commons is going to be the first they hear about the idea.
In summary, I think the other great licences may have been ahead of their time. Creative Commons came along at just the right time, with Web 2.0 happening and all that. And all those people who'd never given a thought to how to share legally were waiting, even if they didn't know it.
Monday, December 04, 2006
Okay, so I can hear you asking already what's my view on the GPL. Should more people use the GPL? Do I think the new draft is doing a good job of improving on version 2? Well, here's my standpoint straight up: before you can discuss the pros and cons of the GPL, you need to figure out where you stand on the philosophy. If you don't agree with the philosophy of free software, you can argue all day with someone who does and never get anywhere.
So when someone says to me "hey Ben, do you think this anti-tivoisation bit's right," I say "do you mean do I think it will stop tivoisation, or do you mean am I happy it's in the new draft?" If they mean the former, I remind them I'm not a lawyer. If they mean the latter, the answer is that I'm not willing to state a view on the philosophy. That's right, I'm a fence sitter.
Okay, the momentum of blogging is carrying me... I will say this much. I am happy that there is such a licence. I am happy that there exists a licence that people who believe in software freedom can use if they choose to. Writing your own on the electronic equivalent of a scrap of paper and shipping it with your software is not a good idea by anyone's estimation.
Andrew Tridgell, who recently won the Free Software Foundation Award for the Advancement of Free Software, said in no uncertain terms at our symposium last week that the GPL is not for everyone - it's not for people who want to restrict the freedom of their software, even if they have a valid or even vital reason to do so. I have to wholeheartedly agree.
And before I go, one last point. Some people out there in law land might think 'What does it matter about the philosophy? If you like what the licence says, that's enough of a reason to use it.' Well, that's not entirely true, because most licensors use the words "General Public Licence version X, or any later version" (emphasis added), and the licence itself clarifies what that means. If you licence like this, you're allowing the licence to be changed based on the underlying philosophy (which the Free Software Foundation strives to stay true to in drafting new versions), so you better be happy with that philosophy. If you're not happy with that philosophy, you can specificly licence under the current version only, but you may as well choose one of the other hundred or so Free and Open Source Software licences out there.
Labels: ben, free software
Wednesday, November 29, 2006
The spark
I've recently been redrafting my Unlocking IP conference paper for publication, and it got me to thinking. Google (as did Nutch, when it was online at creativecommons.org) has a feature for searching for Creative Commons works, as part of Advanced Search. Graham Greenleaf, my supervisor, asked me the other day how they keep up with all the various licences - there are literally hundreds of them when you consider all the various combinations of features, the many version numbers, and the multitude of jurisdictions. Yahoo, for example, only searches for things licensed under the American 'generic' licences, and no others. But Google seems to be able to find all sorts.
Now I'm not one to doubt Google's resources, and it could well be that as soon as a new licence comes out they're all over it and it's reflected in their Advanced Search instantaneously. Or, more likely, they have good communication channels open with Creative Commons.
But it did occur to me that if I were doing it - just little old me all by myself, I'd try to develop a method that didn't need to know about the new licences to be able to find them.
As detailed in my paper, it appears that Google's Creative Commons search is based on embedded metadata. As I have said previously, I understand this standpoint, because it is, if nothing else, unambiguous (compared with linking to licences for example, which generates many false positives).
So if I were doing it, I'd pick out the metadata that's needed to decide if something is available for commercial use, or allows modification, or whatever, and I'd ignore the bit about which licence version was being used, and its jurisdiction, and those sorts of details that the person doing the search hasn't even been given the option to specify.
The challenge
Anyway, the challenge. I have created a web page that I hereby make available for everyone to reproduce, distribute, and modify. In keeping with the Creative Commons framework I require attribution and licence notification, but that's just a formality I'm not really interested in. I've put metadata in it that describes these rights, and it refers to this post's permalink as its licence. The web page is up, and by linking to it from this post, it's now part of the Web.
The challenge is simply this: Which search engines will find it and classify it as commons, creative or otherwise. Will I fool search engines into thinking it's Creative Commons content? Or will they look straight past it? Or will they rise to the challenge and see that what Creative Commons has started is bigger than just their licences, and the Semantic Web may as well be for every licence.
Let's give them a little time to index these pages, and we'll find out.
[post script: I've added a properly Creative Commons licensed page for comparison, that we can use to see when the search engines have come by (this page at least should turn up in search results).]
Tuesday, October 17, 2006
In my last three posts (see part 1, part 2 and part 3), I have been exploring the potential for a search engine that focuses solely on commons content (i.e. works with expanded public rights). Now I’d like to touch on where this idea might fit into the broader scheme of things, including what its shortcomings might be.
At present, Google web search is the benchmark in Internet search. I consider Google to have almost unlimited resources, so for any given feature that Google web search lacks, it is worth considering why they do not have it. In general, I think the answer to this question is either that it will clutter their user interface, it will not be of significant use to the public, or it is computationally intractable. However, given that Google have many services, many in beta and many still in Google Labs, the first problem of cluttering the user interface can clearly be solved by making a new search a new service (for example, Google Scholar). This leaves only the possibilities of the feature not being of significant use, or being computationally intractable.
As this clearly demonstrates, there is no single or simple way to establish works as part of the commons. This may go some way to answering the question of why Google hasn't done this yet. However, Google has implemented at least three of these ideas: in the advanced search, Creative Commons-based usage rights can be specified; in the new Code Search (beta), various text-based licences are recognised by the system; and in Google Book Search (beta), authorship is used to establish public-domain status (in some small subset of Google's scanned books). Google hasn’t done anything all encompassing yet, but it may be that it’s just around the corner, or it may be that Google has figured out that it’s not really what the public want. Depending on how the big players (Google, but also Yahoo and others) proceed, my research may move more towards an analysis of either why so much was done by the big search engines (and what this means to the Unlocking IP project), or alternatively why so little was done (and what this means).
Lastly…
Lastly, I should consider what this idea of a semantic web search engine, as presented, is lacking. First, there is the issue that licence metadata (URLs, if nothing else) need to be entered by someone with such knowledge – the system can not discover these on its own. Second, there are the issues of false positives (web pages that are erroneously included in search results) and false negatives (suitable web pages that are erroneously excluded from search results). The former is the most obvious problem from a user's perspective, and my description here focuses mostly on avoiding these false positives. The latter problem of false negatives is much harder to avoid, and obviously is exacerbated by the system's incomplete domain knowledge, and the inevitable non-standard licensing that will be seen on the web.
Thanks for reading all the way to the end of my last post. If you got this far, stay tuned – I’m sure there’s more to come.
(This is part 3 of a series of posts on semantic web search for commons. For the previous posts, see here: part 1, part 2)
Another possible expansion to the proposed semantic web search engine is to include non-web documents hosted on the web. Google, for example, already provides this kind of search with Google Image Search, where although Google can not distil meaning from the images that are available, it can discover enough from their textual context that they can be meaningfully searched.
Actually, from the perspective of semantic web search as discussed in this series, images need not be considered, because if an image is included in a licensed web page, then that image can be considered licensed. The problem is actually more to do with non-html documents that are linked-to from html web pages, hence where the search engine has direct access to them but prima facie has no knowledge of their usage rights.
This can be tackled from multiple perspectives. If the document can be rendered as text (i.e. it is some format of text document) then any other licence mechanism detection features can be applied to it (for example, examining similarity to known text-based licences). If the document is an archive file (such as a zip or tar), then any file in the archive that is an impromptu licence could indicate licensing for the whole archive. Also, any known RDF – especially RDF embedded in pages that link to the document – that makes usage-rights statements about the document can be considered to indicate licensing.
Public domain works
The last area I will consider, which is also the hardest, is that of public domain works. These works are hard to identify because they need no technical mechanism to demonstrate that they are available for public use – simply being created sufficiently long ago is all that is needed. Because the age of the web is so much less than the current copyright term, only a small portion of the actual public domain is available online, but some significant effort has been and is continuing to be made to make public domain books available in electronic form.
The simplest starting point for tackling this issue is Creative Commons, where there is a so-called 'public domain dedication' statement that can be linked to and referred to in RDF to indicate either that the author dedicates the work to the public domain, or that it is already a public domain work (the latter is a de facto standard, although not officially promoted by Creative Commons). Both of these fit easily into the framework so far discussed.
Beyond this, it gets very difficult to establish that a web page or other document is not under copyright. Because there is no (known) standard way of stating that a work is in the public domain, the best strategy is likely to be to establish the copyright date (date of authorship) in some way, and then to infer public domain status. This may be possible by identifying copyright notices such as "Copyright (c) 2006 Ben Bildstein. All Rights Reserved." Another possibility may be to identify authors of works, if possible, and then compare those authors with a database of known authors' death dates.
But wait, there’s more
In my next and last post for this series, I will consider where Google is up to with the tackling of these issues, and consider the problems in the framework set out here. Stay tuned.
From the starting point of semantic web search just for Creative Commons (CC) licensed works using RDF/XML metadata (see my previous post), we can expand the idea to include other mechanisms and other kinds of documents. For example, the AEShareNet licensing scheme does not promote RDF, but instead web pages simply link to AEShareNet's copy of the licence, and display the appropriate image. A semantic web search engine could then use this information to establish that such pages are licensed, and in combination with an administrator entering the appropriate rights metadata for these licences, such documents can be included in search results. Using this new architecture of link-based licensing identification, we can also expand the Creative Commons search to include pages that link to their licences but for one reason or another do not include the relevant metadata (this is the primary method that Yahoo advanced search uses). Note that such link-based searching will inevitably include false positives in the search results.
The next mechanism that can be considered is that of HTML 'meta' tags. This is part of the HTML format, and is an alternative (and older) way of putting metadata into web pages. The same information can be carried, and given the nature of 'meta' tags they are unambiguous in a similar way to RDF, so false positives should not be a problem.
Another possibility is that the RDF that describes the rights in a page will not be embedded in that page, but will exist elsewhere. This is not too much of an issue, because the search engine can certainly be made capable of reading it and correctly interpreting it. However, it is worth noting that we should have less confidence in such 'foreign RDF' than we would in locally embedded RDF, because it is more likely than otherwise to be a demonstration or illustrative example, rather than a serious attempt to convey licensing information.
Text-based licences
One mechanism that poses significant challenges is what I call 'text-based licences', as compared with RDF-based (e.g. CC) or link-based (e.g. AEShareNet) licences. What I mean by ‘text-based’ is that the licence text is duplicated and included with each licensed work. This raises two problems: What happens if the licence text undergoes some slight changes? And what happens if the licence text is stored in a different document to the document that is a candidate for a search result? (This is common practice in software, as well as uses of the LGPL in multi-page documents. Wikipedia is a prime example of the latter.)
The first question can be answered fairly simply, although the implementation might not be as easy: the search engine needs a feature that allows it to compare a licence text to a document to see if they are (a) not similar, (b) similar enough that the document can be considered a copy, or (c) similar, but with enough extra content in the document that it can be considered a licensed document in its own right.
The other question is more tricky. One possible solution might be to keep a database of all such copies of known licences (what I term 'impromptu' licences), and then, using the functionality of establishing links to licences, record every web page that links to such an impromptu licence as licensed under the original licence. This idea will be useful for all types of text-based licensed, from free software to open content.
But wait, there’s more
Stay tuned for the third instalment, where I will talk about how to utilise non-web content, and the difficulties with public domain works.
Tuesday, October 10, 2006
As part of my research, I’ve been thinking about the problem of searching the Internet for commons content (for more on the meaning of ‘commons’, see Catherine’s post on the subject). This is what I call the problem of ‘semantic web search for commons’, and in this post I will talk a little about what that means, and why I’m using ‘semantic’ with a small ‘s’.
When I say 'semantic web search', what I’m talking about is using the specific or implied metadata about web documents to allow you to search for specific classes of documents. And of course I am talking specifically about documents with some degree of public rights (i.e. reusability). But before I go any further, I should point out that I’m not talking about the Semantic Web in the formal sense. The Semantic Web usually refers to the use of Resource Description Framework (RDF), Web Ontology Language (OWL) and Extensible Markup Language (XML) to express semantics (i.e. meaning) in web pages. I am using the term (small-s ‘semantic’) rather more generally, to refer more broadly to all statements that can meaningfully be made about web pages and other online documents, not necessarily using RDF, OWL or XML.
Commons content search engine
Now let me go a bit deeper into the problem. First, for a document to be considered 'commons' content (i.e. with enhanced public rights), there must be some indication, usually on the web and in many cases in the document itself. Second, there is no single standard on how to indicate that a document is commons content. Third, there is a broad spectrum of kinds of commons, which breaks down based on the kind of work (multi-media, software, etc.) and on the legal mechanisms (public domain, FSF licences, Creative Commons licences, etc.).
So let us consider the simplest case now, and in future posts I will expand on this. The case I shall consider first is that of a web page that is licensed with a Creative Commons (CC) licence, labelled as recommended by Creative Commons. This web page will contain embedded (hidden) RDF/XML metadata explaining its rights. This could be used as the basis for providing a preliminary semantic web search engine, by restricting results to only those pages that have the appropriate metadata for the search. This can then be expanded to include all other CC licences, and then the search interface can be expanded to include various categories such as 'modifiable' etc., and, in the case of CC, even jurisdiction (i.e. licence country). It is worth noting at this point that the details of each individual licence, specifically URL and jurisdiction, are data that essentially represent domain knowledge, meaning that they will have to be entered by an administrator of the search engine.
But wait there’s more
That’s it for now, but stay tuned for at least three more posts on this topic. In the next chapter, I will talk about the (many) other mechanisms that can be used to give something public rights. Then, I will consider non-web content, and the tricky issue of public domain works. Finally, I will look at where Google is at with these ideas, and consider the possible downfalls of a semantic web search engine as described in this series. Stay tuned.
![]()